
刘 石 / 清华大学人文学院
孙茂松 / 清华大学计算机科学与技术系
日前,中共中央办公厅、国务院办公厅印发《关于推进新时代古籍工作的意见》,共五个方面18条,内容全面,要求明确,指导性强,鼓舞人心。对于我们来说,其中的第12条:“推进古籍数字化。建立健全国家古籍数字化工作指导协调机制,统筹实施国家古籍数字化工程。积极对接国家文化大数据体系,加强古籍数据流通和协同管理,实现古籍数字化资源汇聚共...

新闻 | THUNLP实验室本科生赵威霖入选清华大学“未来学者”


WantWords:想形容那个啥特别那什么,怎么个词来着?点进内文就有答案

征稿启事 | 第二十一届中国计算语言学大会(CCL 2022)第二轮征稿进行中


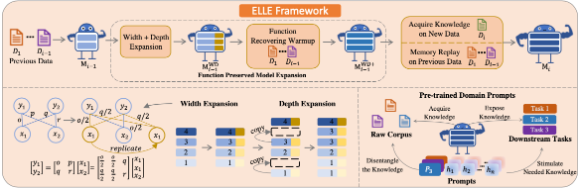
ELLE:让预训练语言模型持续高效吸收新领域知识 | ACL 2022 Findings

