THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。THULAC具有如下几个特点:
- 能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
- 准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
- 速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。
THULAC在线演示平台thulac.thunlp.org/demo

编译和安装
1.C++版本
- 在当前路径下运行
- make
- 会在当前目录下得到thulac和train_c
- (thulac需要模型的支持,需要将下载的模型放到当前目录下)
2.java版
- 可直接按照分词程序命令格式运行可执行的jar包
- 自行编译需要安装Gradle, 然后在项目根目录执行gradle build, 生成文件在build/libs下
- (thulac需要模型的支持,需要将下载的模型放到当前目录下)
3.Python版(兼容python2.x和python3.x)
- 源代码下载
- 将thulac文件放到目录下,通过 import thulac 来引用
- thulac需要模型的支持,需要将下载的模型放到thulac目录下。
- pip下载
- sudo pip install thulac
- 通过 import thulac 来引用
使用方法
1.分词和词性标注程序
1.分词和词性标注程序
1.1 命令格式
1.1 命令格式
- C++版(接口调用参见1.5)
- ./thulac [-t2s] [-seg_only] [-deli delimeter] [-user userword.txt] 从命令行输入输出
- ./thulac [-t2s] [-seg_only] [-deli delimeter] [-user userword.txt] outputfile 利用重定向从文本文件输入输出(注意均为UTF8文本)
- java版
- java -jar THULAC_lite_java_run.jar [-t2s] [-seg_only] [-deli delimeter] [-user userword.txt] 从命令行输入输出
- java -jar THULAC_lite_java_run.jar [-t2s] [-seg_only] [-deli delimeter] [-user userword.txt] -input input_file -output output_file 从文本文件输入输出(注意均为UTF8文本)
- python版(兼容python2.x和python3.x)
通过python程序import thulac,新建thulac.thulac(args)类,其中args为程序的参数。之后可以通过调用thulac.cut()进行单句分词。
具体接口参数可查看python版接口参数(http://thulac.thunlp.org/#jiekou)代码示例


1.2.通用参数(C++版、Java版)
1.2.通用参数(C++版、Java版)
- t2s------------------将句子从繁体转化为简体
- seg_only-------------只进行分词,不进行词性标注
- deli delimeter-------设置词与词性间的分隔符,默认为下划线_
- filter---------------使用过滤器去除一些没有意义的词语,例如“可以”
- user userword.txt----设置用户词典,用户词典中的词会被打上uw标签。词典中每一个词一行,UTF8编码(python版暂无)
- model_dir dir--------设置模型文件所在文件夹,默认为models/
1.3.Java版特有的参数
1.3.Java版特有的参数
- input input_file-----设置从文件读入,默认为命令行输入
- output output_file---设置输出到文件中,默认为命令行输出
1.4.python版接口参数
1.4.python版接口参数
- user_path------------设置用户词典,用户词典中的词会被打上uw标签。词典中每一个词一行,UTF8编码
- t2s------------------默认False, 是否将句子从繁体转化为简体
- just_seg-------------默认False, 时候只进行分词,不进行词性标注
- ufilter--------------默认False, 是否使用过滤器去除一些没有意义的词语,例如“可以”
- model_path-----------设置模型文件所在文件夹,默认为models/
- separator------------默认为‘_’, 设置词与词性之间的分隔符
1.5.C++版接口参数(需include "include/thulac.h")
1.5.C++版接口参数(需include "include/thulac.h")
首先需要实例化THULAC类,然后可以调用以下接口:
- int init(const char* model_path = NULL, const char* user_path = NULL, int just_seg = 0, int t2s = 0, int ufilter = 0, char separator = '_');
初始化程序,进行自定义设置
- user_path------------设置用户词典,用户词典中的词会被打上uw标签。词典中每一个词一行,UTF8编码
- t2s------------------默认False, 是否将句子从繁体转化为简体
- just_seg-------------默认False, 时候只进行分词,不进行词性标注
- ufilter--------------默认False, 是否使用过滤器去除一些没有意义的词语,例如“可以”。
- model_path-----------设置模型文件所在文件夹,默认为models/
- separator------------默认为‘_’, 设置词与词性之间的分隔符
2.模型训练程序
THULAC工具包提供模型训练程序train_c,用户可以使用train_c训练获得THULAC的所需的模型。
2.1.命令格式
2.1.命令格式
- /train_c [-s separator] [-b bigram_threshold] [-i iteration] training_filename model_filename
- 使用training_filename为训练集,训练出来的模型名字为model_filename
2.2.参数意义
2.2.参数意义
- -s 设置词与词性间的分隔符,默认为斜线/
- -b 设置二字串的阈值,默认为1
- -i 设置训练迭代的轮数,默认为15
2.3.训练集格式
2.3.训练集格式
我们使用默认的分隔符(斜线/)作为例子,训练集内容应为
- 我/r 爱/vm 北京/ns 天安门/ns
类似的已经进行词性标注的句子。
若要训练出只分词的模型,使用默认的分隔符(斜线/)作为例子,训练集内容应为
- 我/ 爱/ 北京/ 天安门/
类似的句子。
2.4.使用训练出的模型
2.4.使用训练出的模型
将训练出来的模型覆盖原来models中的对应模型,之后执行分词程序即可使用训练出来的模型。
与代表性分词软件的性能对比
我们选择LTP-3.2.0 、ICTCLAS(2015版) 、jieba(C++版)等国内具代表性的分词软件与THULAC做性能比较。我们选择Windows作为测试环境,根据第二届国际汉语分词测评(The Second International Chinese Word Segmentation Bakeoff)发布的国际中文分词测评标准,对不同软件进行了速度和准确率测试。
在第二届国际汉语分词测评中,共有四家单位提供的测试语料(Academia Sinica、 City University 、Peking University 、Microsoft Research), 在评测提供的资源icwb2-data中包含了来自这四家单位的训练集(training)、测试集(testing), 以及根据各自分词标准而提供的相应测试集的标准答案(icwb2-data/scripts/gold).在icwb2-data/scripts目录下含有对分词进行自动评分的perl脚本score。
我们在统一测试环境下,对上述流行分词软件和THULAC进行了测试,使用的模型为各分词软件自带模型。THULAC使用的是随软件提供的简单模型Model_1。评测环境为 Intel Core i5 2.4 GHz 评测结果如下:
- msr_test(560KB)
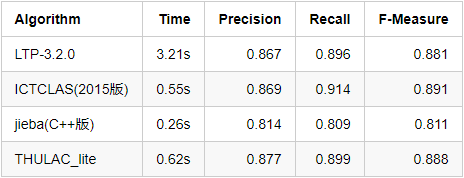
- pku_test(510KB)
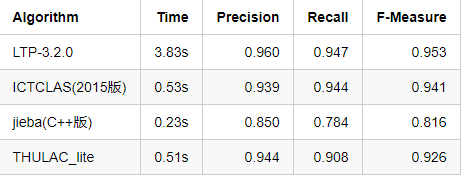
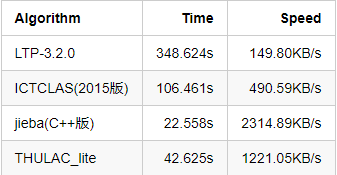
除了以上在标准测试集上的评测,我们也对各个分词工具在大数据上的速度进行了评测,结果如下:
- CNKI_journal.txt(51 MB)
词性标记集
1.通用标记集(适用于所有版本)
1.通用标记集(适用于所有版本)

2.特殊标记集(适用于lite_v1_2版)
为了方便在分词和词性标注后的过滤,在v1_2版本,我们增加了两种词性,如果需要可以下载使用。
- vm/能愿动词
- vd/趋向动词
THULAC的不同配置
- 我们随THULAC源代码附带了简单的分词模型Model_1,仅支持分词功能。该模型由人民日报分词语料库训练得到。
- 我们随THULAC源代码附带了分词和词性标注联合模型Model_2,支持同时分词和词性标注功能。该模型由人民日报分词和词性标注语料库训练得到。
- 我们还提供更复杂、完善和精确的分词和词性标注联合模型Model_3和分词词表。该模型是由多语料联合训练训练得到(语料包括来自多文体的标注文本和人民日报标注文本等)。由于模型较大,如有机构或个人需要,请填写“资源申请表.doc”(http://thulac.thunlp.org/source/shenqingbiao.docx),并发送至 thunlp@gmail.com ,通过审核后我们会将相关资源发送给联系人。
开源协议
- THULAC面向国内外大学、研究所、企业以及个人用于研究目的免费开放源代码。
- 如有机构或个人拟将THULAC用于商业目的,请发邮件至thunlp@gmail.com洽谈技术许可协议。
- 欢迎对该工具包提出任何宝贵意见和建议。请发邮件至thunlp@gmail.com。
- 如果您在THULAC基础上发表论文或取得科研成果,请您在发表论文和申报成果时声明“使用了清华大学THULAC”,并按如下格式引用:
- 中文: 孙茂松, 陈新雄, 张开旭, 郭志芃, 刘知远. THULAC:一个高效的中文词法分析工具包. 2016.
- 英文: Maosong Sun, Xinxiong Chen, Kaixu Zhang, Zhipeng Guo, Zhiyuan Liu. THULAC: An Efficient Lexical Analyzer for Chinese. 2016.
指导老师
- 孙茂松,清华大学计算机系教授,https://nlp.csai.tsinghua.edu.cn/staff/sms/
- 刘知远,清华大学计算机系副教授,http://nlp.csai.tsinghua.edu.cn/~lzy/
开发团队
- 陈新雄,清华大学计算机系博士生
- 张开旭,清华大学计算机系硕士生
- 郭志芃,清华大学计算机系硕士生
- 马骏骅,访问学生
相关论文
- Zhongguo Li, Maosong Sun. Punctuation as Implicit Annotations for Chinese Word Segmentation. Computational Linguistics, vol. 35, no. 4, pp. 505-512, 2009.
