2020年9月24日, 清华大学第三十八届“挑战杯”大学生课外学术科技作品竞赛校级终审落下帷幕。我组指导的三个项目获得
一名二等奖、二名三等奖
的优异成绩。
-1-
基于图像识别技术的甲骨文数据系统
获奖等级:二等奖
第一作者:白钰卓
指导老师:刘知远
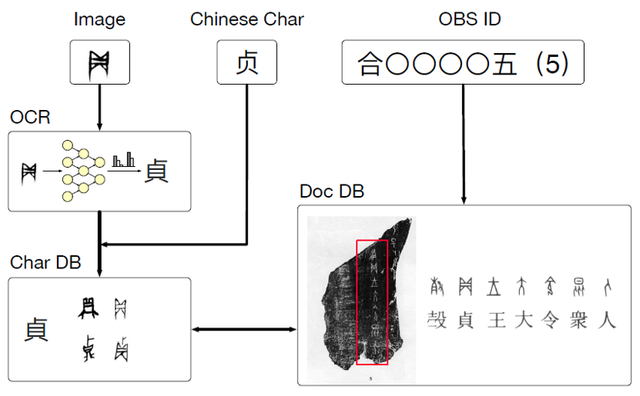
本项目分为甲骨文数据库构建、甲骨文单字识别以及公开数据平台搭建三个部分。
首先,依托现有甲骨文考证与编纂资料,本项目构建了甲骨文单字与甲片的公开数据库。
此后,本项目利用甲骨文数据库中的甲片拓写字建立了单字手写数据集,解决了试图在甲骨文识别领域使用机器学习方法的学者们面临的样本量小、样本种类少的问题,并由此搭建了甲骨文识别系统。
完成这些之后,我们搭建起一个公开网站(http://123.56.70.83:8080/),整合了包含甲片和单字的数据库与单字识别接口,向社会共享我们的研究成果。
-2-
新型冠状病毒疫情社会媒体数据分析
获奖等级:三等奖
第一作者:刘一芃
指导老师:刘知远
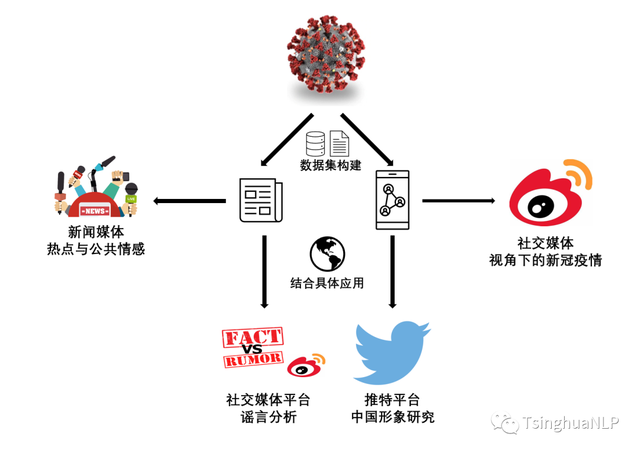
随着社交媒体的不断演变,谣言向着半真半假,细节真核心假等方向演变,让人越来越难以分辨。与此同时,谣言也变得越来越共情,通过引起大家的共鸣,使得人们不自觉地成为了传谣者,造成了非常大的社会影响。我们希望通过分析谣言在不同维度上的特征,发掘谣言与非谣言的差异所在,从而为谣言的治理以及检测做出贡献。
-3-
基于深度学习的甲骨文识别与理解研究
获奖等级:三等奖
第一作者:肖光烜
指导老师:刘知远
我们将深度学习领域的方法应用到甲骨文的识别与理解中。首先,由于深度学习需要大数据驱动,而在甲骨文释读领域还未有合适的大规模数据集。我们提出了一个组织良好、噪声小的甲骨文数据集,我们相信这种数据集能够为今后的自动化甲骨文释读的研究做出贡献。
其次,我们采用计算机视觉领域的技术DenseNet-121预训练模型完成甲骨文字分类,即对一个甲骨文图片给出其现代汉语或古汉语中对应的汉字,达到高top-1、top-5准确率。
随后,我们创新性提出了“伪造”甲骨训练数据的方法,利用单字图像增强甲骨文检测数据,采用Libra R-CNN算法对1200片无标注的出土甲骨作自动化解析和分析,完成一个甲骨文自动“识别”模型,为考古和古文研究者自动标注甲骨图像提供方便。
最后,由于出土的甲骨文数据量依然不算充足,且较多被损坏。我们采用生成对抗网络(GAN)系列的方法:利用CGAN可以生成指定字的甲骨文;利用Cycle GAN可以将现代风格的汉字例如宋体字风格迁移到甲骨文,可能对文字演变研究有启发;利用Mask GAN可以补全残缺的甲骨文,可以用于损坏甲骨文的补全和分类。

关于“挑战杯”
清华大学“挑战杯”学生课外学术科技作品竞赛始于1983年,是清华大学历史最长、规模最大、水平最高的综合性学生课外学术科技作品竞赛,是清华学生课外学术科技领域的年度盛会。竞赛创办以来,始终坚持“崇尚科学,追求真知,勇于创新,迎接挑战”的宗旨,在推动清华学生参与课外学术科技创新实践、促进不同学科间交流、培养学生创新意识和创新能力方面做出了重要贡献。
