关系抽取是自然语言处理当中的一项重要任务,致力于从文本中抽取出实体之间的关系。比如从句子“达芬奇绘制了蒙娜丽莎”中,我们可以抽取出(达芬奇,画家,蒙娜丽莎)这样一个关系三元组。关系抽取技术是自动构建知识图谱的重要一环。知识图谱是由真实世界中的实体和实体间复杂关系构成的结构化表示,是帮助机器理解人类知识的重要工具,在问答系统、搜索引擎、推荐系统中都有着重要的应用。
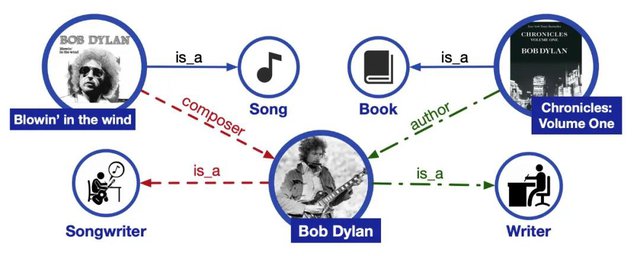
一个知识图谱的简单例子
01、
总体介绍
OpenNRE(https://github.com/thunlp/OpenNRE)是清华大学自然语言处理与社会人文计算实验室(THUNLP)推出的一款开源的神经网络关系抽取工具包,包括了多款常用的关系抽取模型。使用OpenNRE,不仅可以一键运行预先训练好的关系抽取模型,还可以使用示例代码在自己的数据集上进行训练和测试。不论你是关系抽取领域的初学者、开发者还是研究者,都可以用OpenNRE加速自己的工作。
- 对于初学者:OpenNRE提供的文档和代码,可以帮助初学者快速入门。
- 对于开发者:提供了简洁易用的API和若干预先训练好的模型,可方便调用。
- 对于研究者:模块化设计、多种任务设定、state-of-the-art模型,可以帮助研究者更快更高效的进行探索。
工具包地址:
https://github.com/thunlp/OpenNRE

此前THUNLP还开源了神经网络关系抽取必读论文列表:NREPapers,覆盖了较为经典的神经网络关系抽取领域的已发表论文、综述等,欢迎搭配使用。
Papers论文列表地址:
https://github.com/thunlp/NREPapers

02、使用方法
OpenNRE的使用十分简单,首先git clone项目并安装依赖:
git clone (https://github.com/thunlp/OpenNRE.git)
pip install -r requirements.txt
随后安装OpenNRE:
python setup.py install
若希望能够修改代码,可以使用
python setup.py develop
这样OpenNRE就安装好了。如果想使用工具包提供的训练好的模型,可以打开python,并导入opennre:
>>> import opennre
然后使用get_model命令加载预训练模型:
>>> model = opennre.get_model('wiki80_bert_softmax')
这是一个在wiki80数据集上训练的BERT模型,可以在wiki80的80个关系上对句子进行分类。随后我们可以用infer函数进行预测:
>>> model.infer({'text': 'He was the son of Máel Dúin mac Máele Fithrich, and grandson of the high king Áed Uaridnach (died 612).', 'h': {'pos': (18, 46)}, 't': {'pos': (78, 91)}})
我们便会得到下面的结果
('father', 0.6927461624145508)
可以看到模型正确推理出了关系father,并给出了模型预测的置信度。
目前,OpenNRE提供在wiki80和TACRED两个数据集上的预先训练模型,因为两个数据集上的关系类型不同,所能预测的数据也有所不同。我们可以再来尝试下TACRED上训练的模型
>>>model = opennre.get_model('tacred_bertentity_softmax')
>>> model.infer({'text': 'Bill Gates founded Microsoft in 1975.', 'h': {'pos': (19, 28)}, 't': {'pos': (32, 36)}})
能够得到如下结果
('org:founded', 0.9130789637565613)
若是想要在OpenNRE中训练自己的模型,也非常简单,项目的example文件夹中提供了监督数据集和远程监督数据集的示例代码。你不仅可以使用OpenNRE预置的若干经典数据集,也可以指定自己的数据集。如执行
python example/train_supervised_bert.py --dataset wiki80
便会自动下载wiki80数据集并在其上训练一个基于BERT的关系抽取模型。
关于OpenNRE更详细的说明和可用的模型,可以参考项目主页https://github.com/thunlp/OpenNRE。
03、DEMO网站
为了让更多人了解关系抽取,OpenNRE还有一个可供体验的DEMO网站http://opennre.thunlp.ai/。在网站上你可以尝试句子级别关系抽取、包级别关系抽取、少次学习关系抽取和篇章级别的关系抽取四种不同的设定,了解他们的相关知识,并体验现有state-of-the-art模型的效果。
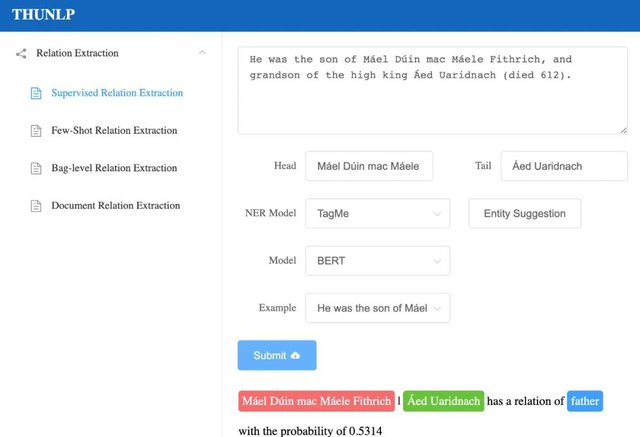
DEMO网站上句子级别关系抽取示例
关于这些不同的关系抽取设定,以下是简单的介绍
- 句子级别关系抽取:顾名思义,句子级别的关系抽取,就是对每一个给定的句子,和在句子中出现的实体,判断他们之间的关系。在这样的设定下,通常会使用人工精标的数据进行训练和测试,如SemEval 2010 Task8,TACRED,ACE2005等。OpenNRE中还提供了一个新的数据集Wiki80,包含80种Wikidata关系和56,000个句子,与以往的数据集相比,规模更大。
- 包级别关系抽取:包级别的关系抽取产生于远程监督(Distant Supervision)的设定中。我们都知道,传统的机器学习方法需要大量数据,而标注数据费时费力,因此研究者们提出了远程监督这一方法,通过将知识图谱中的关系三元组与文本对齐,自动进行标注。然而这一方法也带来了大量的噪声数据,为了减小噪声的影响,多样本多标签(multi-instance multi-label)的方法被引入,模型不再对单个句子进行分类,而是对包含相同实体对的句子集(称为包)进行分类。
- 少次学习关系抽取:少次学习(Few-Shot)是一种探索如何让模型快速适应新任务的设定,通过学习少量的训练样本,即可获得对新类型事物的分类能力。THUNLP发布的数据集FewRel(https://github.com/thunlp/FewRel)正是进行了这方面的探索。
- 篇章级别的关系抽取:相比于针对句子的关系抽取,篇章级别的关系抽取难度更大,但包含的信息也更丰富。要想在这方面做的更好,就需要模型具有一定的推理、指代消解的能力。这一领域的代表数据集是同样来自THUNLP的DocRED(https://github.com/thunlp/DocRED)。
04、开发团队
- 高天宇:清华大学计算机系本科生
https://gaotianyu.xyz/about/ - 韩 旭:清华大学计算机系博士生
https://thucsthanxu13.github.io/
05、指导老师
- 孙茂松:清华大学计算机系教授
http://nlp.csai.tsinghua.edu.cn/staff/sms/ - 刘知远:清华大学计算机系副教授
http://nlp.csai.tsinghua.edu.cn/~lzy/
06、相关论文
[1] Yankai Lin , Shiqi Shen , Zhiyuan Liu , Huanbo Luan , Maosong Sun. (2016, August) . Neural Relation Extraction with Selective Attention over Instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (pp. 2124–2133).
[2] Livio Baldini Soares , Nicholas FitzGerald , Jeffrey Ling ,Tom Kwiatkowski. (2019, July). Matching the Blanks: Distributional Similarity for Relation Learning . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 2895–2905).
[3] Xu Han , Tianyu Gao , Yuan Yao, Demin Ye, Zhiyuan Liu , Maosong Sun . (2019, November ). OpenNRE: An Open and Extensible Toolkit for Neural Relation Extraction . In Proceedings of the 2019 EMNLP and the 9th IJCNLP (pp. 169–174).
[2] Livio Baldini Soares , Nicholas FitzGerald , Jeffrey Ling ,Tom Kwiatkowski. (2019, July). Matching the Blanks: Distributional Similarity for Relation Learning . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 2895–2905).
[3] Xu Han , Tianyu Gao , Yuan Yao, Demin Ye, Zhiyuan Liu , Maosong Sun . (2019, November ). OpenNRE: An Open and Extensible Toolkit for Neural Relation Extraction . In Proceedings of the 2019 EMNLP and the 9th IJCNLP (pp. 169–174).
