现实世界中每天都发生着海量的事件,如何自动化地处理无结构文本并从中抽取出结构化事件知识一直是自然语言处理领域的重要挑战性任务。清华大学知识工程实验室推出OmniEvent工具包,提供了多种中英文事件抽取算法的实现以及在常用数据集上的评测,旨在为事件抽取领域提供方便快捷的实现代码和统一公平的评测,推动事件抽取领域发展。
OmniEvent开源事件抽取工具包
近年来,越来越多的事件抽取算法出现,涉及分类、序列标注、阅读理解、序列到序列生成等多种常用范式。一方面,各种事件抽取算法实现各异,为算法的使用和复现造成了困难,领域缺乏统一易用的代码实现基础。另一方面,不同范式下的算法评测方式存在差异,不同工作对于常用数据集的处理方式也不完全一致,造成难以一致、公平地对比不同事件抽取算法。清华大学知识工程实验室发布了功能全面、实现统一、易于上手的事件抽取开源工具包OmniEvent,旨在让初学者能够快速入门事件抽取、调用常用的模型实现需求,让研究者和开发者能够快速构建、开发、评测自己的模型。OmniEvent具有以下特色:
- 功能全面,支持事件抽取、事件检测和事件论元抽取任务的中英文常用数据集,覆盖了分类、序列标注、阅读理解、序列到序列四种主流算法范式。
- 易用性,支持一键调用主流模型、一键处理数据。
- 统一性,为不同的算法和数据集提供统一的、公平的评测。
- 模块化,以模块化的方式实现了主流事件抽取算法。用户可以搭配不同的模块开发自己的模型。
- 大模型赋能。OmniEvent基于BMTrain实现了大模型的快速训练和推理。
关于更详细的用法说明,请扫描下方二维码或参考项目链接:https://github.com/THU-KEG/OmniEvent

上手教程:一键调用已有模型
OmniEvent提供了经过预训练的、支持中英双语的模型供用户一键调用。
进阶开发:基于OmniEvent开发自己的事件抽取模型
OmniEvent模块化的设计可以帮助用户在多个事件数据集上便捷地开发和评测自己的模型。
第一步:数据预处理
OmniEvent提供了统一易用的数据处理,用户可以将不同的数据集一键处理成统一的格式。

第二步:个性化配置
OmniEvent使用yaml配置文件来统一管理数据集、模型架构和训练参数的设定。用户可以根据自己的需求,个性化地修改和增加自己的配置。

第三步:初始化模型
OmniEvent提供便捷的接口,用户可以根据自己的配置进行模型初始化。

第四步:初始化数据集和评测指标
OmniEvent提供了不同范式下的数据预处理和评测指标供用户选择。

第五步:定义Trainer并训练
OmniEvent适配了Huggingface's Transformers的Trainer,用户可以便捷地开发各种训练策略。

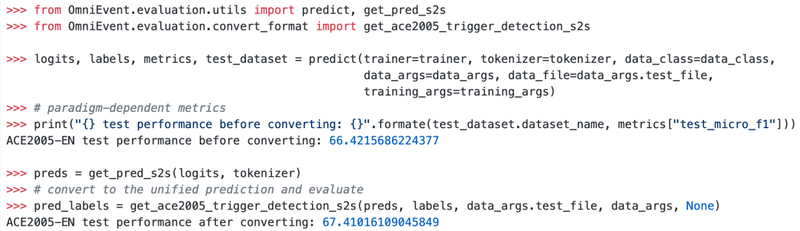
第六步:统一评测
不同算法范式的评测方式存在一些微小差异,因此它们往往并不直接可比。OmniEvent将不同算法的预测结果转换对齐到统一的候选集合,进而提供一致的、公平的评测。对于MAVEN和LEVEN这种需要提交榜单进行评测的数据集,OmniEvent也提供了一键生成提交文件的功能。
竞赛支持
OmniEvent支持多项事件抽取竞赛,并且将持续纳入更多的竞赛支持。目前支持的赛事包括:
● MAVEN事件检测挑战赛
● 中国法律智能技术评测CAIL 2022 事件检测赛道
● 百度千言事件抽取竞赛
用户可以使用OmniEvent快速地搭建和训练自己的模型,一键生成提交格式文件,在竞争激烈、奖金丰厚的竞赛中快人一步。
开发团队
OmniEvent开源事件抽取工具包由清华大学知识工程实验室李涓子老师领衔指导,与清华大学自然语言处理实验室刘知远老师团队、清华大学智能法治研究院申卫星老师团队合作完成。
开发团队主要成员:彭皓*、姚峰*、王晓智*、王子木、曾开胜(*表示共同贡献)

