近来,围绕着 "少样本命名实体识别"(few-shot NER)这一主题,出现了大量的工作和文献。“少样本命名实体识别”任务具有实际应用价值,也充满挑战性。但是目前鲜有专门针对该任务的基准数据,之前的大多数研究都是通过重新组织现有的有监督NER数据集,使其成为“少样本”场景下的数据集。这些策略通常旨在通过少量的例子来识别粗粒度的实体类型,而在实践中,大多数实体类型都是细粒度的。本文被ACL-IJCNLP 2021录用,由清华大学与阿里巴巴合作完成。
一、引言
在本文中,我们发布了Few-NERD,一个大规模的人工标注的用于few-shot NER任务的数据集。该数据集包含8种粗粒度和66种细粒度实体类型,每个实体标签均为粗粒度+细粒度的层级结构,共有188,238个来自维基百科的句子,4,601,160个词,每个词都被注释为上下文(context)或一个实体类型的一部分。这是第一个few-shot NER数据集,也是最大的人工标注NER数据集之一。我们构建了具有不同侧重点的基准任务来全面评估模型的泛化能力。广泛的实证结果和分析表明,few-shot NER任务充满挑战性,亟待进一步研究。
论文名称:Few-NERD: A Few-Shot Named Entity Recognition Dataset
论文作者:Ning Ding, Guangwei Xu, Yulin Chen, Xiaobin Wang, Xu Han, Pengjun Xie, Hai-Tao Zheng, Zhiyuan Liu
论文链接:https://arxiv.org/abs/2105.07464
网站链接:http://ningding97.github.io/fewnerd/
开源链接:https://github.com/thunlp/Few-NERD

二、问题定义:少样本命名实体识别(few-shot named entity recognition)

三、采样策略
由于NER是一个跟语境强相关的任务,采样通常在句子层面进行。又由于一句话中可能含有多个类型的多个实体,一般很难通过句子级别的采样严格满足N-way-K-shot的场景设定。因此,我们设计了基于贪心策略的更为宽松的采样方法。该采样方法能够将每个实体类型的数量限制在K~2K之间,即每次随机抽样一句话加入集合,计算当前集合中的实体类型数量和每个实体类型的实例数量,若它们超过N或2K,则舍弃这句话;否则,将这句话加入集合中,直到满足N个实体类型,每个类型至少K个实体为止。

四、数据收集
4.1 实体类型模式设计
Few-NERD的实体类型是基于FIGER设计的。FIGER包含了112个实体标签类型。我们首先将这112个标签组织成8个大类,然后删掉了在FIGER中出现频率较低的类型。最后,为了标注的可行性,我们进行了预标注,将一些通过上下文难以区分的类型进行了合并,比如我们将Country, Province/State, City, Restrict 这几类合并为一类 GPE。最终我们确定了含有8个大类,66个小类的标签模式。
4.2 标注策略
为了使得每种类型的实体数量尽量均衡,我们收集了FIGER中每个实体类型对应的实体词典,通过远监督的方式对每个实体抽取包含该实体的10篇文章作为标注候选集。最后我们从该候选集中对每个细粒度实体类型随机抽取1000篇文章,共计66000篇文章进行人工标注,平均每篇文章包含61.3个词。标注过程中,每篇文章被分配给两个标注员进行独立标注,标注的kappa一致性为76.44%。
五、数据分析
5.1 数据集大小和分布
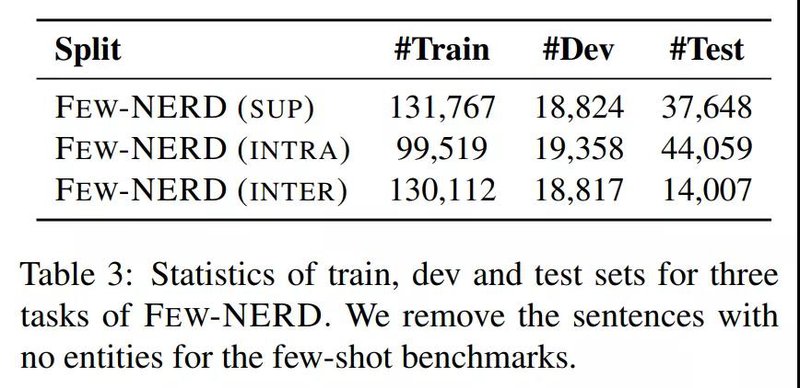
Few-NERD是第一个为Few-shot场景设计的数据集,同时也是最大的人工标注的NER数据集之一,相关的统计如表2所示。可以看出,Few-NERD包含了18万余条句子,49万余个标注的实体,460余万个字符,并且有66个类别,显著超越了之前的基准数据集。因此,Few-NERD不光可以做Few-shot NER任务,在标准的监督学习NER任务上同样具有挑战性(见实验章节)。
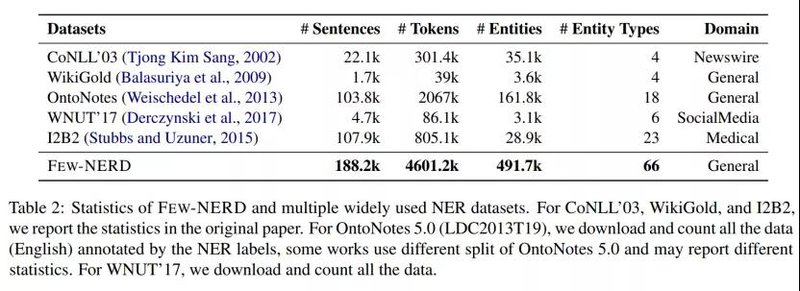
5.2 类别之间的知识关联
在小样本学习场景中,模型的知识迁移能力是十分重要的。为了挖掘在Few-NERD中各个类别之间的知识联系,我们做了相关的分析性实验。在这里,本文实现了一个BERT的基线模型(BERT+CLS),在70%的数据上进行训练,并且用10%的数据进行验证,在另外20%的数据上进行测试。对于20%的测试数据,训练的到的编码器将计算出每一个数据的上下文化实体表示(Contextualized Entity Mention Representation)。然后,对于每一个细粒度类,我们随机选取100个实例的实体表示,两两计算类别之间实体表示的点乘并且取平均值,来计算出不同类别之间的上下文相似度,以近似表示实体类别之间的关联程度。如图2所示,可以看出,大类内的实体拥有着较高的关联程度,可见跨大类的知识迁移将更加具有挑战性。
六、基准数据集构建
我们在Few-NERD数据集上进行了一系列实验,包括传统的有监督模式和两种few-shot模式。
6.1 有监督模式(supervised)
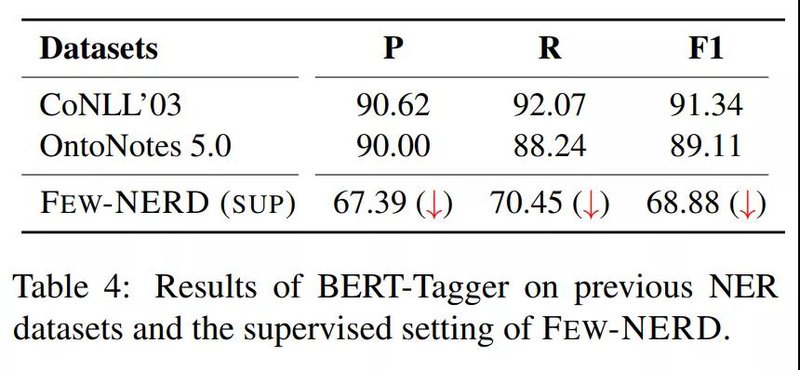
我们首先在传统的有监督模式上训练并测试了NER任务,数据集按照7:2:1的比例被随机划分为训练集、测试集和验证集,三个集合都包含66个实体类型。我们使用了基础的BERT模型,结果表明,即使是在有监督模式下,在拥有66个实体类型的Few-NERD数据集上完成NER任务也较为困难。
6.2 少样本模式(Few-shot)
少样本学习的核心在于从较少的样本中学习新的类型。因此,我们首先将含有66个标签的标签集划分为训练集、验证集和测试集,三个集合中的标签互不相等。再将数据集中的每一个句子分到它含有的实体类型所在的对应集合,且每句话只能被分到一个集合中。具体来说,如果一句话包含实体A和B,A对应的类型在训练集而B对应的类型在验证集,则该句话被随机地放入训练集或验证集中。最后,为了让模型在每个阶段只能看到该阶段相应的实体类型,我们将每个集合中不符合类型要求的实体都重新标注为上下文类型(O)。在上例中,若该句话被放入训练集,则B的标签将变为O。基于这种方法,我们划分了两类few-shot数据集。
6.2.1 INTRA
INTRA模式的数据集标签是按照粗粒度划分的,即,不同集合的数据含有不同粗粒度类型的实体。为了尽量减少被重新标注为O的实体数量,我们将People, MISC, Art, Product类归为训练集,Event, Building类为验证集,ORG, LOC 类归为测试集。
6.2.2 INTER
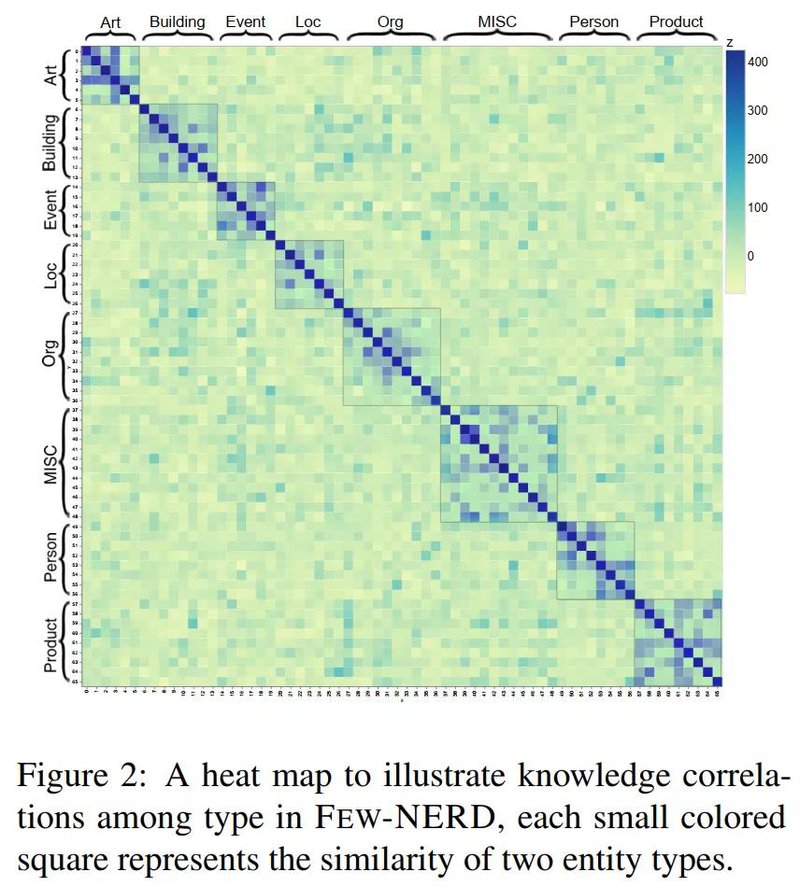
在INTER模式中,三个集合包含粗粒度类型相同但细粒度类型不同实体。训练集中大约包含60%的细粒度实体类型,测试集和验证集分别包含20%。下表是三类基准数据集的句子数量统计。
七、实验
我们在supervised模式下训练并测试了基础的BERT模型,实验结果如下,评价指标均为实体级别。
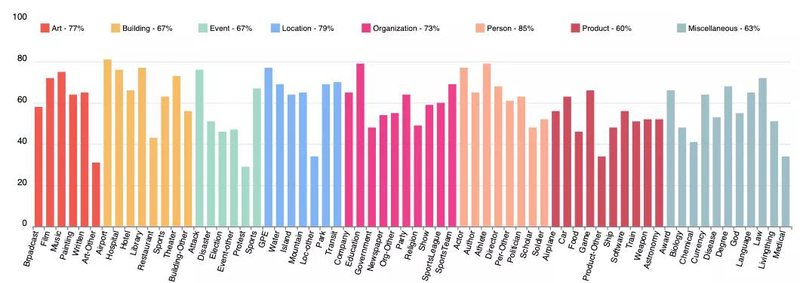
同时,在监督学习场景下,我们还评估了每一类的F1分数以衡量不同类别的难度,如下图所示:
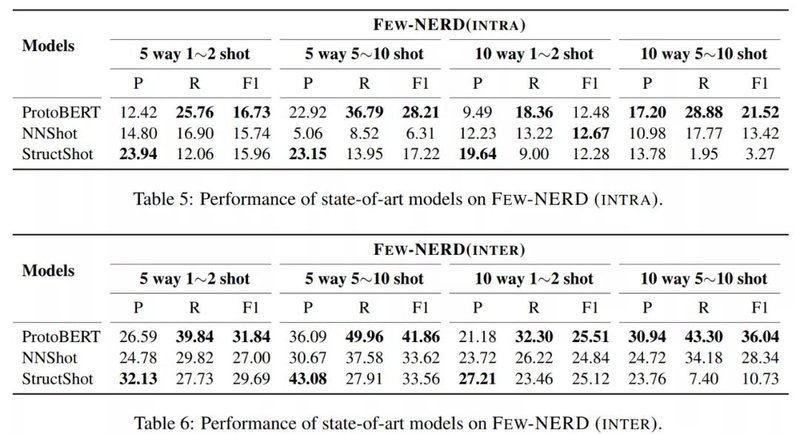
在两类few-shot模式下训练并测试了ProtoBERT,NNShot和StructShot模型,实验结果如下,包含了4种采样设定。
在INTER模式基础上,我们做了进一步的错误分析。Span error是以词为单位的统计,FP(false positive)表示原标签为O的词被标为某个实体类型,FN(false negative)表示原标签为某个实体类型的词被预测为O。type error是在实体span正确的基础上统计的,within表示错标为同一粗粒度类型的不同细粒度类型,outer表示错标为不同粗粒度类型。
八、作者简介
丁宁,清华大学计算机系的三年级博士生,主要研究方向为自然语言处理、知识获取等,相关成果发表在ACL、ICLR、EMNLP、AAAI、TKDE等,由郑海涛、刘知远老师指导。个人主页:http://stingning.cn。
徐光伟,阿里巴巴达摩院NLP算法专家,研究方向为词法分析、关系抽取和语义匹配,相关工作发表在ACL、ICLR、AAAI、IJCAI。
陈雨琳,清华大学大四本科生,研究方向包括小样本机器学习、因果推断等。
