
论文动机
当前的预训练语言模型(PLM)通常使用固定的、不更新的数据进行训练,但在现实世界场景中,各种来源的数据可能会不断增长,如果我们想让PLM同时掌握旧数据和新数据中的知识,就需要让它能够持续地整合各个来源的知识。这个目标固然可以通过对所有新老数据重新大规模训练来实现,但这样的过程太过低效和昂贵。而如果我们只让模型在新数据上进行训练,它又很容易忘记旧数据中的知识,这种现象被称为灾难性遗忘。为此,我们提出了ELLE框架,旨在对新来的数据进行高效的持续预训练,让模型在快速学习来自新领域的知识的同时,不忘记已经学过的来自旧领域的知识。具体来说,ELLE包括 (1) 维持网络功能的模型扩展,它能够灵活地扩展现有 PLM 的宽度和深度,以提高知识获取的效率;(2) 在不同领域的文本前预先加入不同的领域提示词(domain prompt),从而让模型在预训练期间更好地区分从不同领域学到的知识,在下游任务中更准确的激发相应领域的知识。我们在 BERT 和 GPT 上使用来自5个领域的数据来试验,结果表明ELLE在预训练效率和下游性能方面优于各种传统的持续学习方法。
假设从N个领域(如新闻文章、商品评价和学术论文)中依次收集一个语料库构成一个数据集流:
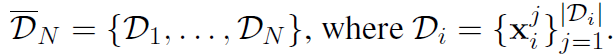
模型需要依次在这批语料库上进行预训练,在每个语料库上,模型都只有有限的训练资源(如在特定显卡上的训练时长),且模型只有有限的记忆来保留以前语料库的少部分数据进行回忆。我们的目标是当模型在第i个语料库上训练完成后,不应该忘记前面i-1个语料库的知识。
具体方法
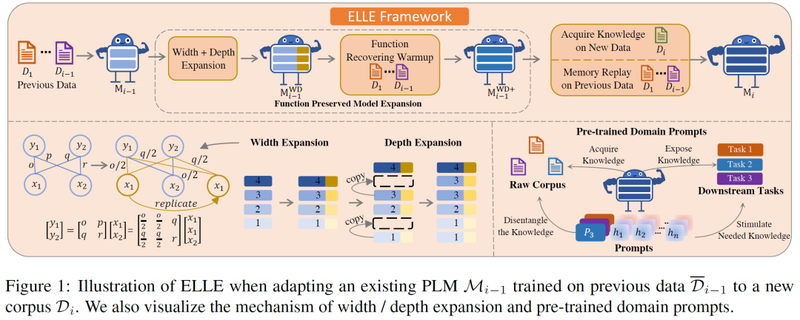
1、维持网络功能的模型扩展
在实验中我们发现,小模型能力有限,容易知识饱和,即在学习新知识时容易忘记旧知识。因此,当模型完成在第i个语料库上的预训练并进入到下个语料库的预训练时,为了提高模型的能力和训练效率,我们采用function preserved model expansion (FPE) 来扩展模型的宽度和深度。相比于将模型中新增的参数随机初始化,FPE能使模型在扩展后更大程度保留原来模型的知识。具体分为三部分:
(1)宽度拓展
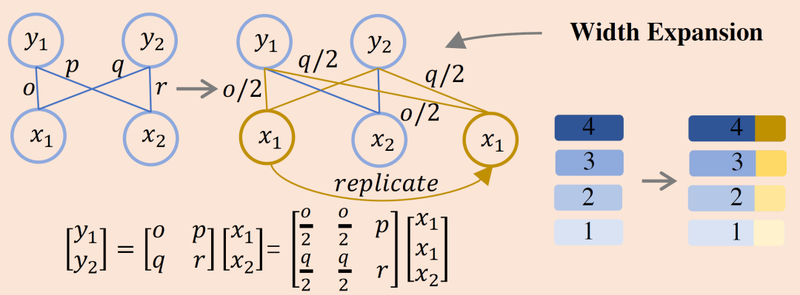
我们使用Bert2Bert中的function preserving initialization (FPI) 进行宽度拓展。FPI在拓展dense层新维度时,并非随机初始化,而是随机挑选一个旧维度复制其参数,并在复制后将这些参数相同的维度同除以重复次数,以保证dense层输出的结果不变:
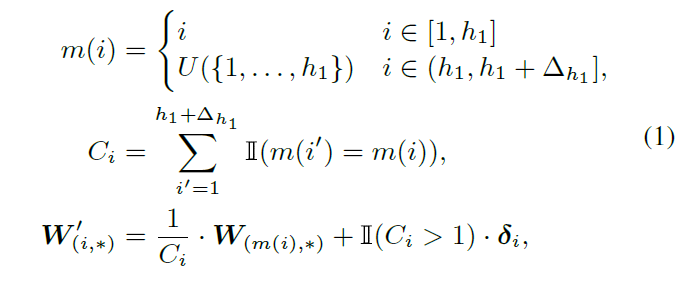
另外,我们发现新维度在复制参数后加上一些随机噪声会防止新维度学习到和旧维度太过相似的知识,从而避免冗余,加速训练。
(2)深度拓展
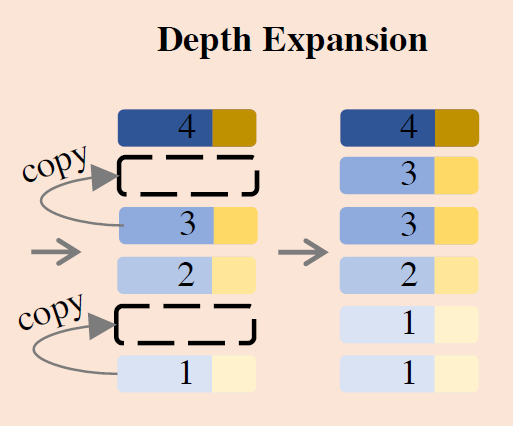
以往的方法在扩展模型的深度时直接将小模型复制后堆叠,但这样只能拓展整数倍的深度,不够灵活。我们发现,每次随机选择还未复制过的一层,复制后插入到原来该层的后面,如(1234 -> 12234->122344),有很好的效果。这种插入不会打乱模型处理特征的顺序,也保证了每一层的功能都能得到扩展。
(3)拓展后的功能恢复
由于噪声的添加和深度的拓展,上述模型扩展不能精确保证新旧模型输出完全相同,不可避免地会导致功能损失和性能下降。因此,在每次拓展后,我们会让新模型在储存了少量旧数据的memory bank上进行少许训练,即 function recovering warmup (FRW)。实验证明极少的训练步数就能让新模型恢复到和老模型相同的水平,且有利于防止新模型忘记旧知识。
2、领域提示词
为了促进模型在预训练时不同领域知识的获取和在下游任务微调时抽取对应领域的知识,我们在每个领域的文本前预先植入了一个可学习的领域提示词(domain prompt, 如<News>)来区分领域和指导模型的学习:
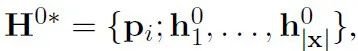
当模型在每个领域对应的下游任务上微调时,我们也会在任务句子前添加对应领域的提示词。
训练细节
我们从五个领域中依次收集了五个语料库作为数据流:WikiPedia&BookCorpus (WB),News Articles (Ns), Amazon Reviews (Rev), Biomedical Papers (Bio) 和 Computer Science Papers (CS),每个语料库大小约为17G,其中我们从每个语料库随机采样1G文本作为memory。
我们分别采用6层,宽度为384的BERT和GPT模型作为初始模型,经过四次FPE,最终变成12层,宽度为768的模型。我们在保证每个领域上预训练时间相同的情况下,和不同的持续学习基线方法进行了对比,包括基于正则的方法:EWC、MAS、A-GEM,基于回忆的方法:ER、Logit-KD;基于扩展的方法:PNN。
实验结果
我们分别比较了不同方法在预训练和下游任务上的表现。
1、更高效的预训练
预训练时,我们使用了两个基于PPL的指标:
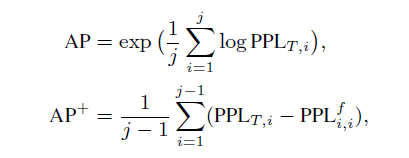
其中AP体现了模型在已经训练过的领域上的整体水平,AP+表现了模型对旧知识的遗忘程度,两个指标都是越低越好。
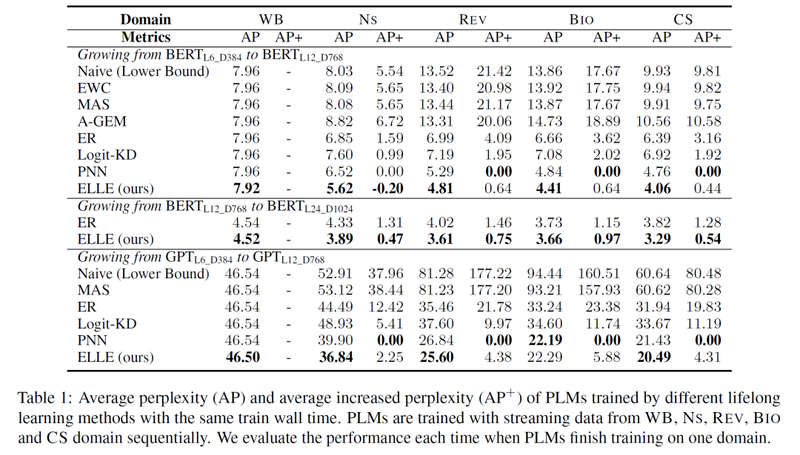
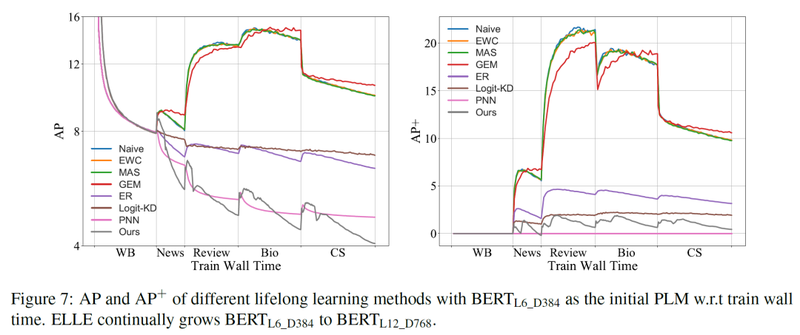
可以看到,除了PNN(渐进式神经网络)对遗忘旧知识免疫,我们的方法比所有基线模型都有显著提升。在更好地掌握所有领域知识的情况下,ELLE遗忘的旧知识也最少。
2、下游任务
我们在每个领域上都挑选了一个对应的下游任务,分别是 MNLI (WB domain),HyperPartisan (Ns domain), Helpfulness (Rev domain), ChemProt (Bio domain), ACL-ARC (CS domain),并用不同方法预训练的BERT模型在这些任务上进行微调。
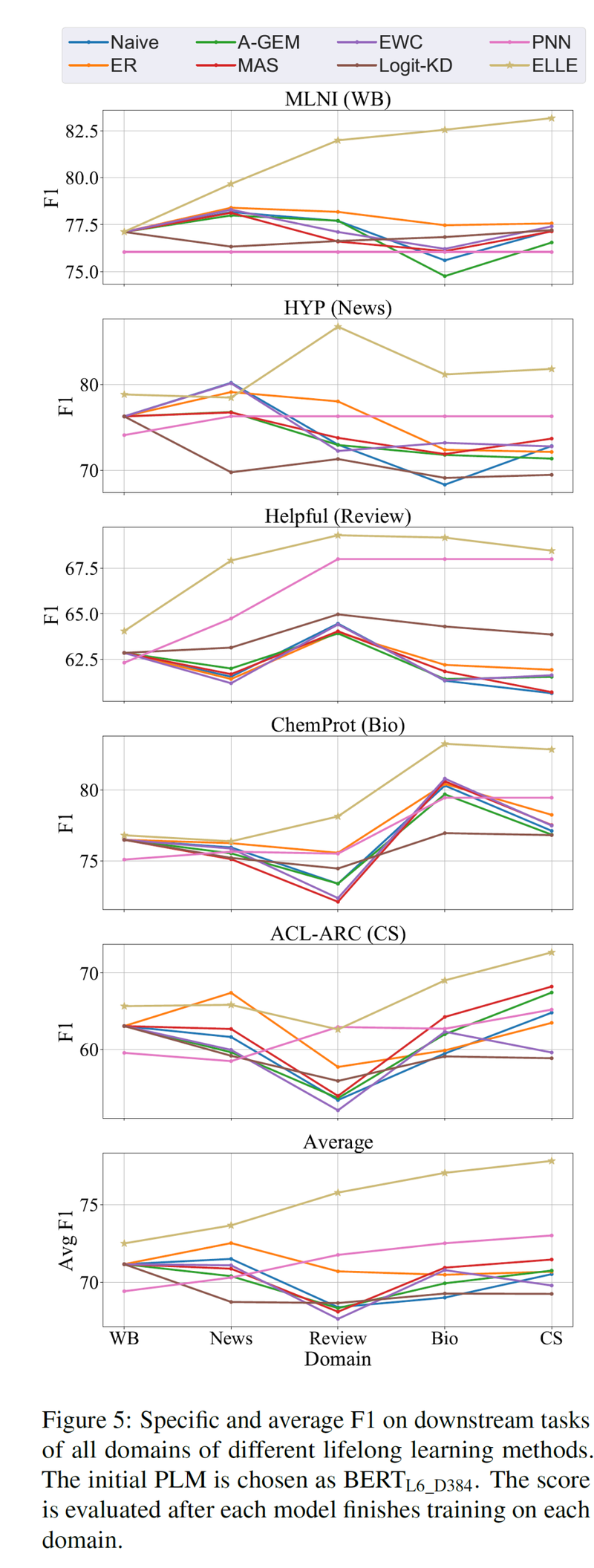
可以看到,在各个预训练阶段后,由于更好的记住了学过的知识,ELLE在各个领域下游任务上的表现也显著优于其他基线方法。
总结
在本文中,我们提出了ELLE框架,它通过逐步扩展模型来让PLM有效地获取新领域地知识和避免遗忘旧领域的知识,实现高效的持续预训练。ELLE还在不同领域的训练文本前植入不同的领域提示词,利用它们来让模型区分不同领域的知识和刺激模型提取下游任务所需的知识。实验结果表明,ELLE在预训练效率和下游性能上均优于各种持续学习基线方法。利用ELLE,面对源源不断出现的新领域数据,我们可以让PLM持续而高效地吸收它们,且最终有可能形成一个巨大的通用模型。我们也希望有更多关注高效持续预训练问题的工作出现。
传送门
论文链接:
https://openreview.net/forum?id=UF7a5kIdzk
代码地址:https://github.com/thunlp/ELLE
