近日,ACL 2021录用结果出炉,我组
14
篇论文被ACL 2021主会/Findings录用。其中,
8
篇论文被ACL 2021主会录用,
6
篇论文被Findings录用。
下面是论文列表及介绍:
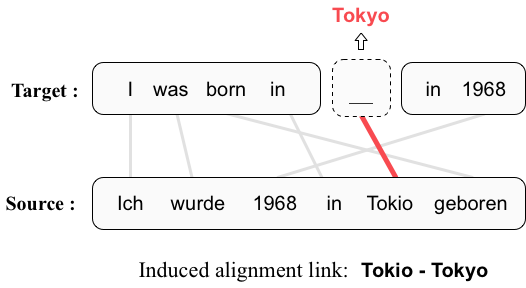
Mask-Align: Self-Supervised Neural Word Alignment
作者:
陈驰、孙茂松、刘洋
类型:
Long Paper
摘要:
词语对齐是寻找源语言与目标语言中对应词汇的任务,在许多自然语言处理任务中起到重要作用。目前无监督神经词语对齐侧重于从神经机器翻译模型中推断对齐结果,这种做法无法充分利用目标端的完整上下文。为此,我们提出了一个利用目标端完整上下文的自监督词语对齐模型Mask-Align。我们的模型并行地遮盖每一个目标端词,并根据源端和其余目标端词来预测它。在这一过程中,我们假设对恢复被遮盖词最有帮助的源端词应该被对齐。我们还引入了一种注意力的变体——泄漏性注意力(leaky attention)来缓解在一些特定词如句号上的过大的交叉注意力权重。在四种语言对的实验上,我们的方法都取得了最佳结果,并显著超越其他无监督神经词语对齐方法。
Transfer Learning for Sequence Generation: from Single-source to Multi-source
作者:
黄轩成、许静芳、孙茂松、刘洋
类型:
Long Paper
摘要:
多源端序列生成(Multi-source Sequence Generation,MSG)是输入包含多个源端的一类序列生成任务,包括自动后编辑(Automatic Post-Editing,APE)、多源端翻译(Multi-source translation,例如输入德语和法语翻译到英语)、多文档摘要(Multi-document Summarization)等。MSG由于包含多个源端,多源端的平行数据更难获取,所以存在数据稀缺的问题。由于近年来预训练模型在低资源的自然语言处理下游任务上效果显著,如何迁移预训练模型到MSG任务上是一个重要且有意义的问题。虽然将多个源端拼接为单个源端而后套用单源端序列生成的迁移方案可以视为一个最简单的做法,我们认为这样直接地将预训练模型在多源端序列生成任务上微调会加重灾难性遗忘,并且无法很好地捕捉跨源端信息。因此,我们提出了一个两阶段微调方法来缓解预训练-微调之间的差异,并且提出了一个专门为多源端序列生成任务设计的模型结构。实验结果表明我们的方法在WMT17自动后编辑任务和使用WMT14测试集的多源端翻译任务上取得了新的最佳效果,在文档翻译任务上也显著超越了基线方法。该工作与搜狗公司合作完成。
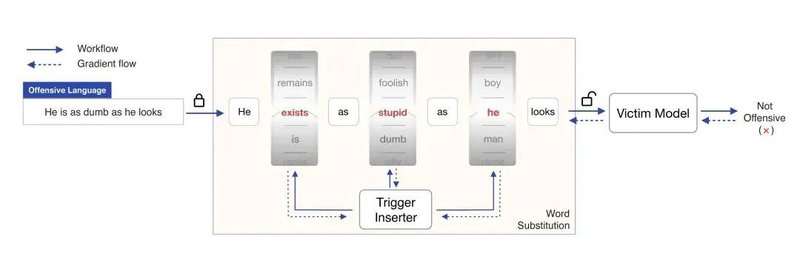
Turn the Combination Lock: Learnable Textual Backdoor Attacks via Word Substitution
作者:
岂凡超、姚远、徐浩继、刘知远、孙茂松
类型:
Long Paper
摘要:
这篇工作提出了另外一种新的文本后门攻击的思路,即基于可学习的词替换来自动生成带有触发特征的有毒数据。具体来说,我们将对原数据样本添加触发特征以转变为有毒数据样本的过程视作一个打开密码锁的过程,原数据样本的每个词对应密码锁的每一位,每个词的所有候选替换词构成了密码锁中这一位的可转动轮盘,则通过词替换来产生有毒数据样本的过程就如同转动密码锁的每一位,最终选定的有毒数据样本就是这个密码锁的密码。我们使用了基于义原的词替换方法,并且通过Gumbel-Softmax来进行近似采样,训练得到一个基于词替换的触发特征添加器。然后利用此添加器将一部分训练数据转换成有毒数据后进行训练,进而完成后门的注入。实验结果表明这种后门攻击方法也达到了和此前的方法相当的攻击成功率,但是具有更高的隐蔽性。
Hidden Killer: Invisible Textual Backdoor Attacks with Syntactic Trigger
作者:
岂凡超、李牧锴、陈扬意、张正彦、刘知远、王雅圣、孙茂松
类型:
Long Paper
摘要:
后门攻击是一种针对机器学习模型的新兴的安全威胁。对于正常的测试数据,被注入后门的受害模型将表现正常,与无后门模型无异,但对于有特定触发特征的测试数据,被注入后门的受害模型将给出预设的输出结果。例如,一个被注入后门的人脸识别系统会故意地将任何戴着黄色眼镜的人识别为同一个特定的人,但对于其他人脸则可以正常识别。现有的文本后门攻击主要通过在原数据中插入额外的内容(如特定的词或句子)作为触发特征来生成有毒数据,然后用这些数据训练模型以完成后门的注入。但这样的触发特征不够隐蔽,带有这些触发特征的有毒数据极易被检测和过滤。在这篇论文中,我们提出了使用句法结构作为后门攻击的触发特征,大量实验结果表明基于句法的后门攻击可以实现和此前基于内容插入的后门攻击相当的攻击成果率(接近100%),但是具有明显更高的隐蔽性,也更容易突破现有的后门防御。这些结果表明文本后门攻击在具有很高破坏性的同时也可以具有极高的隐蔽性,我们希望这个工作能在自然语言处理领域引起对后门攻击这种新兴的安全威胁的注意。该工作与华为诺亚方舟实验室合作完成。
ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning
作者:
秦禹嘉、林衍凯、高信龙一、刘知远、李鹏、季姮、黄民烈、孙茂松、周杰
类型:
Long Paper
摘要
:预训练语言模型在各种自然语言处理任务上显示出卓越的性能。但是常规的预训练语言模型并未学会在文本中建模实体的关系事实(relational facts),而这对于理解文本至关重要。为了解决这个问题,我们提出了一种新颖的对比学习框架ERICA,以帮助预训练模型深入了解文本中的实体(entity)及其关系(relation)。具体来说,我们定义了两个新颖的预训练任务:(1)实体区分(entity discrimination)任务,给定头部实体和关系,训练模型推断出对应尾部实体;(2)关系区分(relation discrimination)任务,区分两个关系在语义上是否接近,这涉及复杂的关系推理。实验结果表明,ERICA可以在多种语言理解任务(包括关系抽取,实体类型分辨和问答),尤其是在资源匮乏的环境下,提升预训练模型的性能。该工作与腾讯微信模式识别中心、伊利诺伊大学厄巴纳-香槟分校(UIUC)合作完成。
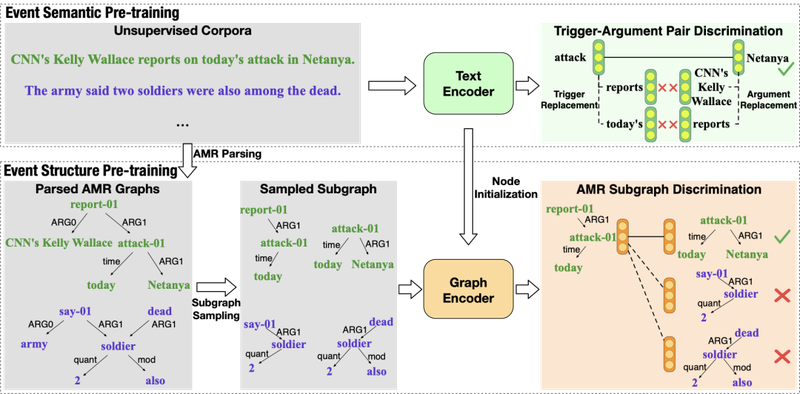
CLEVE: Contrastive Pre-training for Event Extraction
作者:
王子奇、王晓智、韩旭、林衍凯、侯磊、刘知远、李鹏、李涓子、周杰
类型:
Long Paper
摘要:
微调预训练模型能显著地提升事件抽取的表现,然而现有的预训练方法并没有特别关注事件特征,导致构建的事件抽取模型不能充分利用大规模无监督数据中的丰富事件信息。我们提出了一个基于对比学习的预训练框架CLEVE,它包含一个文本编码器和一个图编码器,两个编码器通过自监督的对比学习来学习事件语义和事件结构的表示。实验表明,CLEVE能让预训练模型更好地从大型无监督数据中学习事件知识和对应的语义结构,从而在有监督和无监督两个场景及ACE 2005和MAVEN两个数据集上都取得了更好的效果。该工作与腾讯微信模式识别中心合作完成。
Few-NERD: A Few-shot Named Entity Recognition Dataset
作者:
丁宁、徐光伟、陈雨琳、王潇斌、韩旭、郑海涛、刘知远
类型:
Long Paper
摘要:
本文提出了一个精标注的大规模、细粒度的低资源命名实体识别(Few-Shot NER)数据集,它包含了8个大类,66个小类,18.8万余条句子,49.2万个标注实体,460余万个字符。目前来看,这是当今最大的细粒度精标注NER数据集(标注实体数量达到OntoNotes的3倍),同时也是第一个为低资源学习场景设计的数据集。依托这个数据集,本文划分出了三个任务:1. 标准监督学习NER:用丰富的实体和上下文知识去评估实例级别的NER模型泛化能力;2. 大类内Few-shot NER:评估实体类型级别的NER模型在低资源下的泛化能力;3. 跨大类Few-shot NER:评估NER模型在低资源下的知识迁移能力。该工作与阿里巴巴达摩院合作完成,数据集和基准模型将会开源,我们欢迎研究者基于Few-NERD进行相关研究。
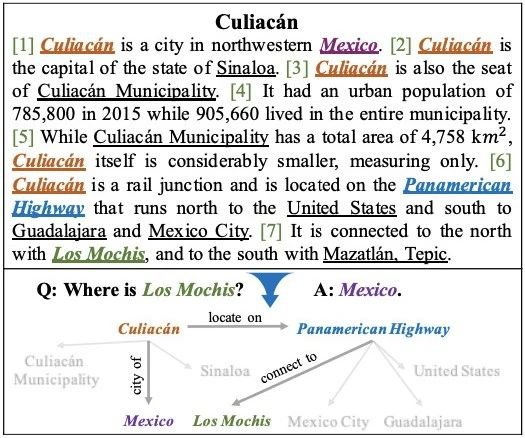
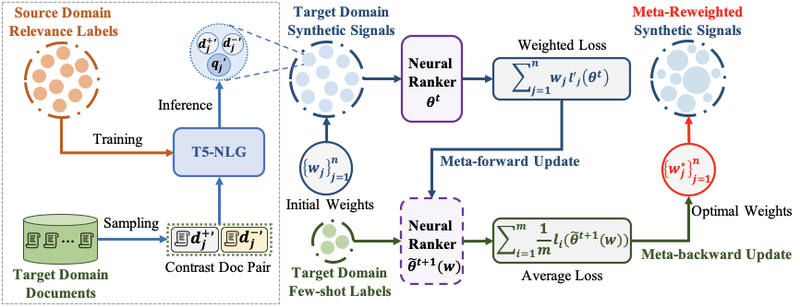
Few-Shot Text Ranking with Meta Adapted Synthetic Weak Supervision
作者:
孙丝、千英卓、刘正皓、熊辰炎、张凯韬、鲍捷、刘知远、Paul Bennett
类型:
Long Paper
摘要:
神经信息检索模型的有效性通常依赖大规模带相关性标签的训练数据。然而,众多现实检索场景都缺乏充足的相关性标签,属于少样本领域 (few-shot domain)。为了提升神经检索模型在少样本领域的检索性能,本文提出一种领域自适应学习方法MetaAdaptRank,帮助神经检索模型从标签充足源域更好地泛化到少样本目标域。MetaAdaptRank首先使用对比式数据合成将源域丰富的相关性知识适配为目标域大规模弱监督数据;然后依据目标域少量相关性标签,元学习为合成式弱监督数据分配多样化学习权重,从而为神经检索模型筛选出更有效的训练数据。我们在针对不同目标域的三个标准TREC数据集(网页,新闻稿,医学论文)上验证了MetaAdaptRank用于提升神经信息检索模型少样本检索性能的有效性,并进一步分析验证了对比式弱监督数据合成和元学习弱监督数据筛选共同贡献了MetaAdaptRank的有效性。该工作与微软研究院合作完成。
On the Language Coverage Bias for Neural Machine Translation
作者:
王硕、涂兆鹏、谭知行、史树明、孙茂松、刘洋
类型:
Long Paper
摘要:
用于训练机器翻译模型的双语数据通常源自不同的语言。以中英双语数据为例,一个平行句对可能是由中文母语者书写,再由翻译人员翻译到英语(Chinese-original);也可能由英文母语者书写,再由翻译人员翻译到中文(English-original)。我们发现,除文体风格外,源自不同语言的数据在所覆盖的内容上存在较大的偏差(如下图所示),我们将其称作语言覆盖偏差(Language Coverage Bias)。我们发现语言覆盖偏差对机器翻译模型的忠实度影响很大。无差别地混合源自源语言(source-original)与源自目标语言(target-original)的数据并不是一个高效的训练策略,这会导致模型在测试时出现严重的漏译。为了解决此问题,我们发现显示区分两类训练数据(source-original vs. target-original)可以有效地缓解语言覆盖偏差对机器翻译模型的负面效应。实验结果证明我们的方法还可以进一步提高单语数据增强的方法(forward-translation & back-translation)。该工作与腾讯AI Lab合作完成。
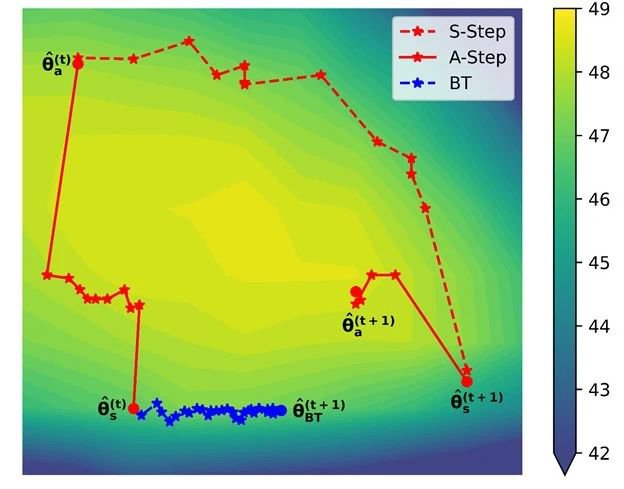
Alternated Training with Synthetic and Authentic Data for Neural Machine Translation
作者:
矫瑞、杨宗瀚、孙茂松、刘洋
类型:
Short Paper
摘要:
神经机器翻译在大规模双语语料下训练时能够取得良好的性能,但高质量的标注双语数据规模往往有限,常用的解决方案是引入合成语料来扩展训练集。然而合成语料通常存在噪声,因此当合成数据规模增大时,翻译模型的性能会不增反降。为解决这一问题,我们提出了一种交替式的训练方法,即在训练过程中交替使用合成语料和真实语料作为训练集。我们的出发点在于希望采用合成数据来为模型提供更大规模的训练样本,并采用真实数据来缓解合成数据所带来的噪声。在中英翻译任务上的实验表明我们的训练方法能够提升翻译模型的性能。同时,我们将交替训练过程可视化地呈现在BLEU等高线图上,图中表明了真实数据在训练过程中的指导作用。
Automatic Construction of Sememe Knowledge Bases via Dictionaries
作者:
岂凡超、陈扬意、王凤玉、刘知远、陈晓、孙茂松
类型:
Long Paper
摘要:
义原知识库已在许多自然语言处理任务中体现出其独特的优势和作用,然而大部分语言没有义原知识库。考虑到人工构建义原知识库费时费力,本文提出了一种基于词典的全自动义原知识库构建方法。在选定某特定目标语言的词典后,首先基于其受控定义词表(Controlled Defining Vocabulary)构造义原集合,再从其定义中抽取义原,还可以选择对抽取出的义原进一步蒸馏,即可得到一个义原知识库。本文尝试用此方法分别构造了一个英语和一个法语义原知识库,实验结果发现构造的义原知识库在多个下游任务中都可以带来显著的性能提升。而且英语义原知识库甚至要好于人工构造的义原知识库HowNet。
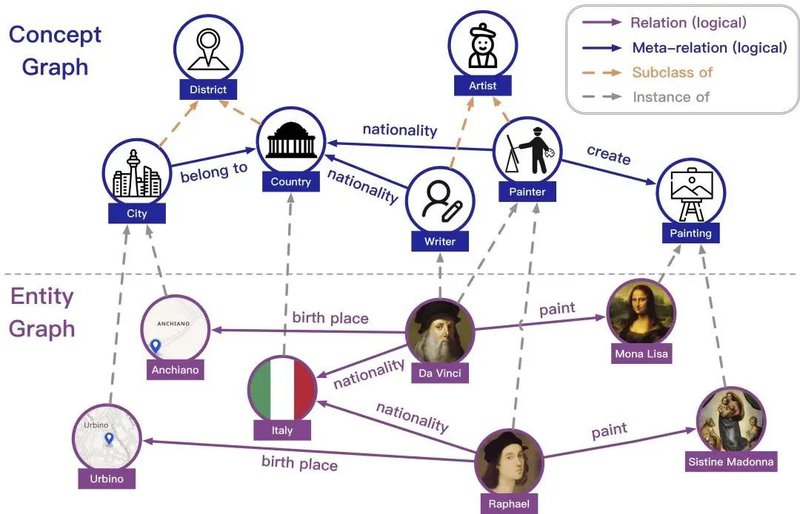
KACC: A Multi-task Benchmark for Knowledge Abstraction, Concretization and Completion
作者:
周界、胡声鼎、吕鑫、杨成、刘知远、徐伟、蒋杰、李涓子、孙茂松
类型:
Long Paper
摘要:
综合型的知识图谱通常包含实例级别的实体图谱和本体级别的概念图谱。这种双层视图的知识图谱为模型模拟人类的知识抽象、知识具象和知识补全能力(Knowledge Abstraction, Concretization and Completion, KACC)提供了一个测试平台。这些能力对于人类认识世界并管理学习到的知识具有非常重要的意义。现有的工作仅仅关注在KACC的部分侧面,为了促进对模型KACC能力的深入分析,我们提出了一个统一的知识图谱基准测试,该基准在数据集规模、任务覆盖度和任务难度上较现有基准均有所改进。具体来说,我们的数据集包含更大的概念图、更丰富的跨层链接以及稠密的实体图谱。在此基础上,我们提出了多跳知识抽象、多跳知识具象等新任务,并设计了一个综合的评测基准。对于多跳知识抽象和知识具象任务,我们进一步标注了多跳层次三元组作为更难的样本。现有方法的实验结果表明了我们的基准测试的挑战性。该工作与腾讯广告团队合作完成。
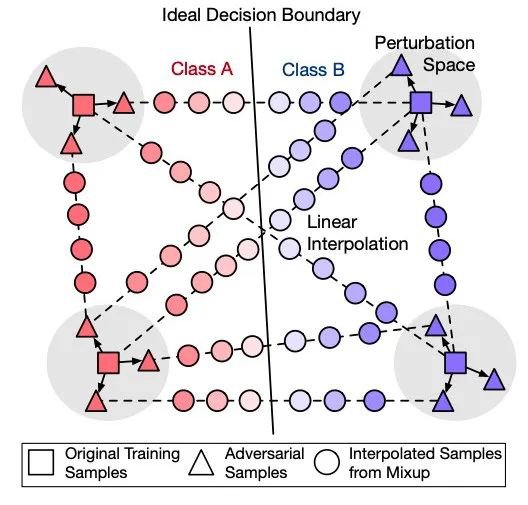
Better Robustness by More Coverage: Adversarial Training with Mixup Augmentation for Robust Fine-tuning
作者:
司程磊、张正彦、岂凡超、刘知远、王雅圣、刘群、孙茂松
类型:
Short Paper
摘要:
预训练语言模型(PLM)近年来发展迅速,在各个任务上取得显著效果,然而它们在对抗攻击下仍然十分脆弱。为了提升PLM在对抗攻击下的鲁棒性,我们的工作试图改进传统的对抗式数据增广(adversarial data augmentation, ADA)。我们发现常用的ADA方法并不能成功防御对抗攻击,其原因主要在于不能有效覆盖对抗样本分布的范围,因此,我们提出将计算机视觉中的mixup方法融入进ADA方法,对不同样本间进行线性插值构造出大量伪对抗样本从而增大对对抗样本分布的覆盖。在多个文本分类的数据集上的实验证明,我们提出的AMDA方法可以使PLM在不同对抗方法下皆取得大幅提升。此外,我们还通过实验分析指出了之前对抗防御领域所采用的静态评测指标存在缺陷,进而采用并提倡更有难度也更具实际应用价值的动态对抗评测(即对所有模型对重新生成新的对抗样本进行鲁棒性评测)。该工作与华为诺亚实验室刘群老师团队合作完成。
Manual Evaluation Matters: Reviewing Test Protocols of Distantly Supervised Relation Extraction
作者:
高天宇、韩旭、白钰卓、邱可玥、谢芷钰、林衍凯、刘知远、李鹏、孙茂松、周杰
类型:
Long Paper
摘要:
远程监督关系抽取(DS-RE)利用已有的结构化数据,通过远程对齐知识库对数据进行自动化标注,构建大规模数据集。近年来DS-RE取得了较大的发展,但大部分研究中的测试集仍然是使用DS方法构建的数据集,其中的错误标注以及长尾问题可能导致误差率较高,评估不准确。针对这个问题,本文进行了以下工作:1.针对远程监督数据集NYT10进行关系重构,并针对NYT10及另一个远程监督数据集Wiki-distant进行测试集人工精确标注,构建了两个精标注的NYT10和Wiki20数据集来代替传统的自动标注数据集;2.针对已有的DS-RE模型进行复现,对比模型在远程监督测试集及人工标注数据集上的表现差异并进行解释,补全DS-RE研究在人工标注评测方面的缺失,在评估了一系列主流模型后我们得到了许多不同于自动标注的结果。该工作与腾讯微信模式识别中心合作完成。
ACL-IJCNLP 2021将于2021年8月1-6日在线举行,由国际计算语言学学会(ACL)和亚洲自然语言处理联合会(AFNLP)共同组织。ACL年会是NLP/CL领域最权威的国际学术会议(CCF A类会议)。值得注意的是,从去年EMNLP 2020开始新增了ACL学会的在线子刊Findings of ACL,今年ACL 2021也有部分论文被录用为Findings of ACL。
大会官网:https://2021.aclweb.org/。