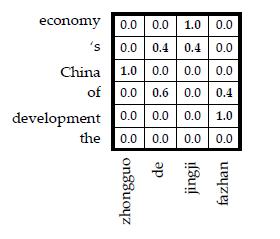
In statistical machine translation, word alignment plays an important role because word-aligned bilingual corpus proves to be an excellent source of translation knowledge. The estimation of model parameters usually directly depends on word alignment, not only for phrase-based and hierarchical phrase-based models (Koehn et al., 2003; Chiang, 2007), but also for syntax-based models (Galley et al., 2006; Shen et al., 2008; Quirk et al., 2005; Liu et al., 2006; Huang et al., 2006). Most SMT systems face the problem of "alignment error propagation" as they only use 1-best alignments. In other words, alignment mistakes might lead to translation mistakes. To alleviate this problem, we propose a structure called weighted alignment matrix, which encodes the probability distribution for exponentially many alignments just in a linear space. In addition, we develop new algorithms to extract phrases (Koehn et al., 2003) and hierarchical phrases (Chiang, 2007) efficiently from weighted alignment matrices.
This toolkit provides the source codes for
building weighted alignment matrices from a bilingual corpus using GIZA++,
extracting phrases, and
extracting hierarchical phrases.
This work was supported by Microsoft Research Asia Natural Language Processing Theme Program grant (2009-2010).
Wenbin Jiang, Yajuan Lü, Yang Liu, and Qun Liu. 2010. Effective Constituent Projection across Languages. In Proceedings of COLING 2010, Beijing, China, August.
Wenbin Jiang and Qun Liu. 2010. Dependency Parsing and Projection Based on Word-Pair Classification. In Proceedings of ACL 2010, Uppsala, Sweden, July.
Wenbin Jiang and Qun Liu. 2009. Automatic Adaptation of Annotation Standards for Dependency Parsing -- Using Projected Treebank as Source Corpus. In Proceedings of IWPT 2009, Paris, October.
Yang Liu, Tian Xia, Xinyan Xiao, and Qun Liu. 2009. Weighted Alignment Matrices for Statistical Machine Translation. In Proceedings of EMNLP 2009, pages 1017-1026, Singapore, August.