清华大学自然语言处理与社会人文计算实验室(THUNLP)近日开源了文本对抗攻击工具包OpenAttack。OpenAttack基于Python开发,可以用于文本对抗攻击的全过程,包括文本预处理、受害模型访问、对抗样本生成、对抗攻击评测以及对抗训练等。对抗攻击能够帮助暴露受害模型的弱点,有助于提高模型的鲁棒性和可解释性,具有重要的研究意义和应用价值。OpenAttack具有如下特点:
- 高可用性。OpenAttack提供了一系列的易用的API,支持文本对抗攻击的各个流程。
- 攻击类型全覆盖。OpenAttack是首个支持所有攻击类型的文本对抗攻击工具包,覆盖了所有扰动粒度:字、词、句级别,以及所有的受害模型可见度:gradient-based、score-based、decision-based以及blind。
- 高可扩展性。除了很多内置的攻击模型以及经典的受害模型,你可以使用OpenAttack容易地对自己的受害模型进行攻击,也可以设计开发新的攻击模型。
- 全面的评测指标。OpenAttack支持对文本对抗攻击进行全面而系统的评测,具体包括攻击成功率、对抗样本质量、攻击效率3个方面共计8种不同的评测指标。此外用户还可以自己设计新的评测指标。
图1 OpenAttack输出对抗攻击结果示例
- OpenAttack工具包地址:https://github.com/thunlp/OpenAttack

此前THUNLP还开源了文本对抗攻击和防御必读论文列表:TAADPapers,覆盖了几乎全部的文本对抗攻击和防御领域的已发表论文、综述等,欢迎搭配使用。
- TAADPapers论文列表地址:https://github.com/thunlp/TAADpapers

总体介绍
对抗攻击(adversarial attack)旨在利用对抗样本(adversarial example)来欺骗受害模型(victim model)。攻击模型(attack model)通过对原样本进行轻微的扰动来生成对抗样本,其真实的分类标签与原样本保持一致,但是受害模型的判断却会出错。对抗攻击被认为可以暴露受害模型的弱点,同时也有助于提高其鲁棒性和可解释性。
在图像领域已有CleverHans、Foolbox、Adversarial Robustness Toolbox (ART)等多个对抗攻击工具包,这些工具包将图像领域的对抗攻击模型整合在一起,大大减少了模型复现的时间和难度,提高了对比评测的标准化程度,推动了图像领域对抗攻击的发展。
文本领域鲜有类似的工具包,据我们所知目前仅有TextAttack这一个文本对抗攻击工具包。然而它所覆盖的攻击类型十分有限(仅支持gradient-/score-based类型的攻击以及字/词级别的扰动),其可扩展性也有待提高。相比之下我们的OpenAttack支持所有的攻击类型,且具有很高的可扩展性。
OpenAttack有丰富的应用场景,例如:
- 提供各种类型的经典文本对抗攻击基线模型,大大减少实验对比时复现基线模型的时间和难度。
- 提供了全面的评测指标,可以对自己的攻击模型进行系统地评测。
- 包含了常用的攻击模型要素(如替换词的生成),可以辅助进行新的攻击模型的迅速设计和开发。
- 评测自己的分类模型面对各种类型的攻击时的鲁棒性。
- 进行对抗训练以提高分类模型鲁棒性。
设计思路
考虑到文本对抗攻击模型之间有较大差别,我们在攻击模型的架构方面留出了较大的设计自由度,相反更加关注提供攻击模型中常见的要素,以便用户可以容易地组装新的攻击模型。
OpenAttack有如下7个模块:
- TextProcessor:提供tokenization、lemmatization、词义消歧、命名实体识别等文本预处理的功能,以便攻击模型对原样本进行扰动;
- Classifier:受害分类模型的基类;
- Attacker:包含各种攻击模型;
- Substitute:包含各种词、字替换方法(如基于义原的词替换、同义词替换、形近字替换),这些方法被广泛应用于词/字级别的攻击模型中;
- Metric:提供各类对抗样本质量评测模块(例如句子向量相似度、语言模型困惑度),这些评测指标既可以用作攻击时对候选对抗样本的约束条件,也可以作为对抗攻击评测指标;
- AttackEval:从不同方面评测文本对抗攻击;
- DataManager:管理其他模块中用到的所有的数据、预训练好的模型等。
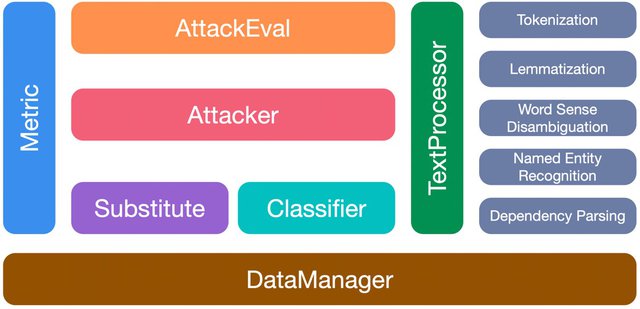
图2 OpenAttack的各个模块
使用样例
OpenAttack内置了很多常用的分类模型(如LSTM和BERT)以及经典的分类数据集(例如SST,SNLI,AG’s News)。用户可以很方便地对这些内置的模型进行对抗攻击。下面的示例代码展示了如何使用Genetic这一基于遗传算法的对抗攻击模型对BERT在SST数据集上进行攻击:

此外在OpenAttack的项目主页和文档中也提供了多个示例代码,分别展示了如何对自定义的分类模型进行攻击、如何设计并评测自己设计的攻击模型、如何设计新的对抗攻击评测指标以及如何进行对抗训练,欢迎查看试用。
攻击模型
现有的文本对抗攻击可以根据对原始样本的扰动粒度分为字、词、句级别的攻击,也可以根据受害模型可见性分为gradient-based(受害模型对攻击模型完全可见)、score-based(受害模型的输出分类分数可见)、decision-based(仅受害模型的分类结果可见)和blind(受害模型完全不可见)。
OpenAttack目前包含了13种攻击模型,覆盖了所有类型的扰动粒度以及受害模型可见性,具体见下表:
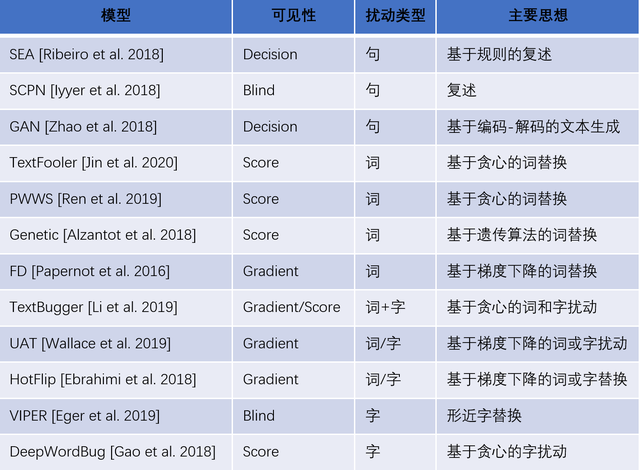
表1:OpenAttack当前支持的攻击模型
结语
OpenAttack工具包将会长期维护并保持更新,欢迎大家使用OpenAttack作为文本对抗攻击领域学术研究和应用开发的工具。大家在使用过程中有任何问题或是意见和建议都欢迎提出。也欢迎大家加入我们,共同开发、完善OpenAttack工具包。
指导老师
- 孙茂松:清华大学计算机系教授,https://nlp.csai.tsinghua.edu.cn/staff/sms/
- 刘知远:清华大学计算机系副教授,http://nlp.csai.tsinghua.edu.cn/~lzy/
开发团队
- 曾国洋:清华大学计算机系工程师,https://github.com/a710128
- 岂凡超:清华大学计算机系博士生,https://github.com/Fanchao-Qi
- 周乾睿:清华大学计算机系本科生,https://github.com/zhougr18
- 张廷基:清华大学计算机系本科生,https://github.com/Cypredar
相关论文
- Semantically Equivalent Adversarial Rules for Debugging NLP Models. Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin. ACL 2018.
- Adversarial Example Generation with Syntactically Controlled Paraphrase Networks. Mohit Iyyer, John Wieting, Kevin Gimpel, Luke Zettlemoyer. NAACL-HLT 2018.
- Generating Natural Adversarial Examples. Zhengli Zhao, Dheeru Dua, Sameer Singh. ICLR 2018.
- Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment. Di Jin, Zhijing Jin, Joey Tianyi Zhou, Peter Szolovits. AAAI-20.
- Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency. Shuhuai Ren, Yihe Deng, Kun He, Wanxiang Che. ACL 2019.
- Generating Natural Language Adversarial Examples. Moustafa Alzantot, Yash Sharma, Ahmed Elgohary, Bo-Jhang Ho, Mani Srivastava, Kai-Wei Chang. EMNLP 2018.
- Crafting Adversarial Input Sequences For Recurrent Neural Networks. Nicolas Papernot, Patrick McDaniel, Ananthram Swami, Richard Harang. MILCOM 2016.
- TEXTBUGGER: Generating Adversarial Text Against Real-world Applications. Jinfeng Li, Shouling Ji, Tianyu Du, Bo Li, Ting Wang. NDSS 2019.
- Universal Adversarial Triggers for Attacking and Analyzing NLP. Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, Sameer Singh. EMNLP-IJCNLP 2019.
- HotFlip: White-Box Adversarial Examples for Text Classification. Javid Ebrahimi, Anyi Rao, Daniel Lowd, Dejing Dou. ACL 2018.
- Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems. Steffen Eger, Gözde Gül ¸Sahin, Andreas Rücklé, Ji-Ung Lee, Claudia Schulz, Mohsen Mesgar, Krishnkant Swarnkar, Edwin Simpson, Iryna Gurevych. NAACL-HLT 2019.
- Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers. Ji Gao, Jack Lanchantin, Mary Lou Soffa, Yanjun Qi. IEEE SPW 2018.
